OERA Open Source Initiative
The OERA Open Source Initiative (OERA OSI) is a project to define, create, and refine a series of production quality components which can serve as a sound basis for those creating their own OERA implementations. The primary focus will be components which would form a portion of the Common Infrastructure portion of the standard OERA model, but we will not exclude contributions for other sorts of helper classes which might be used as part of a Data Access, Business Logic, or UI layer.
The initial focus will be on Object Oriented implementations. If there is demand, we will consider an alternative set of procedural model implementations, but it is felt that those most likely to be implementing OERA are likely to be on current releases. In particular, we will utilize the latest OpenEdge version which is shipping to customers as needed and expect that those who need an earlier version will take responsibility for backporting, although we have no objection to people posting backported versions for the use of others.
This project is intended as an open source effort, hopefully with community involvement. Computing Integrity will initially take responsibility for defining a structure, but it is hoped that community involvement will evolve that structure. If there become enough contributors actively participating, we will deal then with issues of governance, but for the present it is expected that consensus will suffice.
The OERA OSI Group
The OERA OSI Forum
Note that you must join the group to view the forum. Join the group here
For services related to this material, see my website.
OERA OSI Project
This is the project for tracking work on the OERA Open Source Initiative. Use it for feature requests, issue tracking, bug reports and the like. Use the forum for general discussion and add comments to individual pages of content as appropriate.
OERA OSI Group
This is the group for the OERA Open Source Initiative. All those interested in keeping track of the work on this project should join this group in order to receive e-mail notifications.
If you would like to start proposing the design of a new component or would like to contribute a component, please just create a new book page and parent it into the structure in an appropriate place.
If you are commenting on a specific contribution or proposal which already has its own page, please add comments to the page so the page author can respond and consider integrating your material into the page.
Use the forum below for early stage proposals, discussion of general principles, issues of interaction, etc.
The OERA OSI Forum
General Principles
This section will be used to provide general guidelines for the operation and construction of components for this project.
Identity
It seems to me that there is an interesting question that runs through several of these threads which has to do with identity. For some things, we often think of the identity of the person as established by a user name and password or some biometric or other means. But, it seems to me that there are other functions which depend on physical identity. E.g., for an AppServer agent starting up, if we are going to have it determine its configuration based on some service, then how do we know which agent it is? This could also apply to security polices such as Joe is entitled to download general ledger details when he is sitting at his desk, but not when he is dialed in from a remote location. I would be interested in people's ideas about both what kind of identities are needed and how it is that they might get assigned.
Standard Questions
There are a number of questions we want to ask about each candidate service. These include:
1. What kind of service is it? I.e., is it one service for a network? One per application? One for a system? One per session? Can it be replicated without change of function?
2. What inputs does it need?
3. What outputs will it return?
4. Who uses it and how frequently?
5. What does it depend on and how often?
6. How is it managed?
I will also note that while we have been using the currently popular term "service", there are places where we might want instead to use the term factory or the term manager. Service seems particularly appropriate when the component is centralized and broadly used, but also seems to fit some per session uses. Not key, but something to think about whether there is any convention we might want to adopt.
Business Logic Components
This category will be used to discuss principles of building business logic components, sample business logic component code, and helper classes for business logic.
Common Infrastructure Components
Components in this category are intended for use as part of the Common Infrastructure of the OERA layering.
Auditing Service
Bruce Gruenbaum:
The Auditing Service logs access and changes to data and stores away the state of the data at the time that an event took place. It is subtly different from logging in that logging is about keeping track of the fact that things happened whereas auditing is about keeping track of exactly what happened.
Thomas Mercer-Hursh:
And, given the availability of database auditing facilities, there is a question of what constitutes an auditable event, especially in relation to a logable event. I'm not 100% sure that there is a clean separation versus the notion that there are some log events which have interest for auditing.
Initial content adapted from an exchange on PEG.
Authentication Service
Bruce Gruenbaum:
The Authentication Service is responsible for authenticating a user when the session starts up. All it does is determine that the user is known to the system and that the user's credentials have been authenticated. In most applications, the Authentication Service is a façade that allows implements
its authentication through an LDAP or other authentication service. The Authentication Service also provides the Connection Factory and other services with the credentials they need to authenticate the user of this session against other targets.
Thomas Mercer-Hursh
Are non-humans, i.e., services also authenticated and how?
Does this return a token which is then used to indicate that the current session is authenticated?
Initial content adapted from an exchange on the PEG
Authorization Service
Bruce Gruenbaum
The Authorization Service is responsible for verifying and applying permissions and policies to the user that is logged in. Again, most of its implementation resides in an LDAP or other service, but the Authentication Service allows for this to be abstracted so that LDAP can be swapped out for something else.
Thomas Mercer-Hursh
One of the interesting questions about authorization is who asks the question. E.g., it doesn't do much good to have a user session ask whether or not it is authorized to do something unless the path to the controlled resource is also working with the same authorization. E.g., take the question of whether the user is authorized to update the Customer table. If the session has a database connection, it is pretty hard to keep it from updating the Customer table, no matter what the service says unless the user is confidently trapped in an application which is going to conform to this limitation. Ideally, no one could access the Customer table directly so that one would have to go through the mediation of a Customer data access object to do anything to the Customer table. But, there is also a question of overhead since, if this data access object is stateless, then it needs to keep banging away on the authorization service for every record.
Initial content adapted from an exchange on the PEG
Caching Service
Bruce Gruenbaum:
The Caching Service is responsible for storing data that may be referred to at a future point in time by this physical session and thereby reduce processing time. Caching with OpenEdge is simply a store of data. In muti-threaded environments, the cache can be self cleaning based on a LRU algorithm or something similar.
Thomas Mercer-Hursh:
I wonder if caching is a service or a property of data access. E.g., take a cache of state and province codes. Does one need to do anything more than create a set object containing that data and remember to not throw it away so that it can be re-used. Or, are you thinking that the way one "remembers" to reuse it is to keep it is something like a temp-table of Pro.Lang.Objects with tags so that they can be provided to any requester. And, of course, one has caches which are complete sets and caches which are simply most recently used, with or without a limit. Not to mention the problem of how to know when the cache is stale.
Initial content adapted from an exchange on PEG.
Connection Factory
Bruce Gruenbaum:
The Connection Factory establishes and maintains connections to external targets - databases, AppServers and other TCP/IP targets. It really is responsible for all connectivity to anything that is not in the same process. It handles connection pooling and connection failure. It also abstracts connections into logical connections so that the physical service being requested can be treated separately from the logical connection. This means that a single database connection could be used for multiple logical databases and the same is true for AppServers and any other target.
Thomas Mercer-Hursh
It seems to me that there are a couple of issues here. One of them relates to your environment service, e.g., the environment tells me that I should be able to connect to the billing database so the connection factory can be expected to make that connection as long as the security service agrees that I am personally authorized.
Another relates to the question of local versus centralized sources of information. E.g., if asked to make a connection to a billing database, where does the information come from about where that database resides and what parameters are needed to connect to it?
I am also curious about the technical aspect of the database connection since ABL doesn't have the sort of connection object which is is some 3GLs. With a connection object, one instantiates it and makes it available to whatever needs it and one passes in SQL queries for it to process and has a generic method for handling a result set. Possibly we have the tools to do this in ABL now ... or possibly not ... but is it really something we would want to do? And, if not, then how is the connection made available to the session unless it is established in a top level procedure and then everything is run below that? Also, in the absence of a connection object, how does on centralize things like knowing that a connection has been lost and possibly re-establishing itself?
Initial content adapted from a thread on the PEG
Content Management Service
Bruce Gruenbaum:
The Context Management Service is designed to keep track of data that is needed to reestablish a logical session's context on subsequent interactions with a target. People will argue whether context should be stored on the client or the server or both. In my experience, a framework has to provide support for all three options - client, server and both. If one views a set of interactions with a set of targets as a set conversations, context management is about determining where you last left off in the conversation with a specific target.
Thomas Mercer-Hursh:
Or, in the case of AppServer agents, being able to continue the conversation even though you weren't the one who had the last exchange.
Bruce Gruenbaum:
Session management is about reducing the amount of time it takes to determine which target you are talking to.
Thomas Mercer-Hursh:
Agree that one needs all three. One of the interesting twists is supporting a uniform context management solution across multiple client types.
Initial content adapted from an Exchange on the PEG
Environment Service
Bruce Gruenbaum:
The Environment Service determines the context in which the framework is being run. This presupposes that the framework will run in many configurations. Although I am going to talk about it in the context of an OpenEdge application, this is a service that I have written for OpenEdge, Java and C#.
Thomas Mercer-Hursh:
So, from your description, I take it that this service is one per session? Does it have any inputs? Is its output something like an XML document containing a list of cans and can't or does it simply have a bunch of methods of the form "canIDoSuchAndSuch()? Do you see this as a persistent component in each session which is queried repeatedly by the application to determine whether or not it can do something or is it a startup function that passes the information on to the application and goes away? Where does it get its information? E.g., if it is running for a client session with no DB connection, is it going to connect to a DB in order to get the information? Or, do we have a local service and a provider service which is a central source for the information?
Initial content adapted from an exchange on the PEG
Exception Handling Service
Bruce Gruenbaum:
Let me start out by saying that this is service that hitherto has not worked as well for me in OpenEdge as it does in Java/.NET. In a nutshell, it is a service that is responsible for receiving exceptions that have been caught somewhere. The Exception Handling Service receives the exception, logs it to an exception log and then looks for a class that has been designed to process the exception in some way. The trick is to have a standard way of processing all exceptions so that the user never experiences a Java/C#/OpenEdge exception/error condition that has not been handled.
Thomas Mercer-Hursh:
We could use a little more help from PSC on this score, but we are certainly closer than we were to making it possible. To be sure, it is a difficult area to design well, especially since we haven't been given the ability to provide multiple exceptions on a single throw. I have been thinking that I should do a new instance of my exception and condition handling classes in the context of the 10.1C exception handling to help support richer use.
Initial content adapted from an exchange on PEG
Logging Service
Bruce Gruenbaum:
The Logging Service logs every event that takes place in the system that is set to be logged. On a Windows platform these logs are optionally written to the Event Log. Where such services exist on other platforms they are used as appropriate. Exceptions are automatically logged with their complete stack traces.
Thomas Mercer-Hursh
"set to be logged" seems to imply getting configuration data on what to log.
I suppose that it should be a choice, but I can't say that I am personally fond of dumping this sort of information into a generic OS log ... it should be someplace where it is more conspicuous.
This should also include an option for centralized logging. E.g., whenever an unhandled exception occurs, I want that to show up in a central location.
Initial content adapted from an exchange on PEG.
Session Management Service
Bruce Gruenbaum:
Session Management and Context Management are closely related but subtly different. A client may have many connections to several different targets. Each of those connections may be termed a session and its lifetime is the duration of the connection. That is a physical session. Many times though, the client makes repeated connections to a target and often to more than one target at a time. It may often be possible to reduce the amount of processing time involved by reusing an authentication token. Thus a logical session may span many connections to many different targets. The Session Manager is responsible of tracking data that is related to the logical session.
Thomas Mercer-Hursh
My own inclination would be to think of a session as the duration of an AVM instance, regardless of what happened to connections since one could have all sorts of interesting complexities like:
1. connect to A
2. connect to B
3. disconnect from A
4. disconnect from B
Perhaps one also wants to have a session-connection instance, one per.
And, for a client, if they are connecting to a state free AppServer, there will be many many connections during one session.
Initial content adapted from an exchange on PEG.
Data Access Components
This category will be used to discuss principles of building data access components, sample data access component code, and helper classes for data access.
For initial background reading, consult OERA Strategies: Object-Oriented or Not?
Enterprise Service Components
This category will be used to discuss principles of building enterprise service components, sample enterprise service component code, and helper classes for enterprise services.
UI Components
This category will be used to discuss principles of building UI components, sample UI component code, and helper classes for ABL UI.
It may be necessary or appropriate for us to subdivide this are according to the UI technology since contributions might deal with a variety of technologies.
UI Service Components
This category will be used to discuss principles of building UI service components, sample UI service component code, and helper classes for UI services.
UI services are components which run on the server and provide an interface between clients and the business logic layer. They contain no UI themselves. It is likely that some will be specific to a given UI and will serve to isolate the business logic layer from the specifics of the particular UI. Some may be UI independent.
Low-level Infrastructure Components
While the primary focus of the OERA OSI is service components to implement OERA architectures, any framework also has a need for a library of basic, low level components on which to base other code. Thus, the OERA OSI will include a library of such low level components.
Collection Classes for OO Relationships
In Object-Oriented programming one object interacts with another object via a relationship, i.e., a direct link between the two objects. When this relationship is one to one, then one object will simply have a reference to the other object. But, if the relationship is one to many, then there is a need for an intermediary structure to hold the references for the many end of the relationship. No intermediary structure is shown in a UML diagram, since the notation on the relationship indicates the nature of the relationship, but when implementing the model in OO code, generic infrastructure is required to manage this relationship. These generic infrastructure classes are often called “collection” classes.
The 1 end (“parent”) of the 1 to many relationship has a reference to the collection and the collection contains references to the objects at the many end (“child”) of the relationship. By navigating the methods of the collection class, the parent can access the members of the collection, i.e., can traverse the relationship.
In my 2006 implementation of collection classes ( http://www.oehive.org/CollectionClasses ) I used the Java model for collection and map classes and followed it quite closely, except for the differences which I believed were indicated by the choice of temp-tables as the basis of implementation. The current revision was originally motivated by the desire to add modern error handling facilities and to switch from an internal iterator to a separate iterator, i.e., to enable multiple iterators on the same collection. In the process of considering a later version of the Java libraries and whether or not the functionality of the original collection classes should be extended, several ideas developed for possible alternatives to the use of temp-tables, at least for some types of collections.
Further consideration made us realize that the Java collection hierarchy covers much more than just collections for object relations, e.g., queues, so it was decided to step back from the Java implementation and concentrate first on the needs for defining relations. This, and a general desire to make these core objects as small and light as possible has led to a proposed structure which has little relationship to the Java hierarchy. In particular, the initial release will focus strictly on the needs for implementing relations. The various other possible collection and map type functionality will be considered at a later time.
This documentation is being made available prior to development of code and testing in order to allow for feedback and comment, so that there is opportunity to influence the development.
Core Concepts - Order
The most common form of relationship collection is ordered only by the order in which elements are added to the collection. The parent using the collection may have added the elements in some special order, but most commonly the order is of no significance because any operation performed on the collection will be performed on all members of the collection and it is thus order is of no significance.
It is possible to conceive of a set in which there was no predictable order (called a Bag in Java parlance), but it is unlikely that this provides any better utility than order by addition and so is not included in the current work. In particular, it is unclear how one insures that each element in a Bag is processed once and only once.
A second type of relationship connection is ordered by identity, i.e., by the identifier for the object (in ABL, this is given by int(ObjRef). Like addition order, one will typically build such a collection completely, make one or more iterations through all the elements doing some processing, and then delete the collection with or without persisting. The major difference with a collection ordered by identity over one ordered by addition is that it is faster and easier to identify whether a particular object is part of a collection. This could be important if the parent needs to enforce no duplicates (see Core Concepts – Duplicates).
A third type of relationship collection is ordered by some other value, typically an attribute of the elements. These relationships are fairly uncommon in traditional 3GL OO, but might seem more “natural” to an ABL programmer because of the analog to tables and keys, but in most relationships, the order is not relevant and the use of a key would be unnecessary overhead. In these collections, values are added as key/value pairs instead of just individual object elements, where the key is the basis for ordering and the value is the object element. In Java terminology, these are known as Map classes rather than Collection classes.
In our hierarchy we are providing two forms of the key/value classes, one which is merely ordered by the key, but where duplicate keys are allowed and the other where the collection is ordered by the key and the key is unique and thus provides a unique identifier for a specific object. Java Map classes only provide the later type.
Core Concepts – Duplicates
In any ordinary object relationships, one would never have duplicates because it simply makes no sense to have the same object twice on one end of a relationship. Some Java Collection objects enforce this rule and others don’t.
In designing these collection classes, we decided to omit checking for duplicates for two reasons. First, in any implementation which does not provide direct indexing by object identity, searching every element already in a collection to see if it matches a proposed new element is expensive overhead. Second, in most cases, the very nature of adding elements to a collection will not lead to duplicates, so incurring the overhead of checking for duplicates is wasted effort. Compare, for example, to populating a temp-table with the lines for a particular order based on the persisted data – would you feel the need to include logic to check to see whether an order line was already in the table or would you assume, rightly, that sequential reading of the persisted data will result in no duplicates.
We are electing to provide a Contains() operator on our collection classes which the parent can use to test for duplicates if a situation arises in which it may not be clear if a particular object is already in the collection.
With key-value sets there is some question about what one means by “no duplicates”. In the Java Map classes, no duplicate keys are allowed based on the idea that each key should uniquely identify an object, but there is no restriction on duplicate objects, i.e., the same object can be pointed to by different keys. This makes little sense in a relationship collection. Consequently, we have provided two types of key/value pair objects, one of which limits to unique keys and the other of which doesn’t. The former is like the Java Map class and the later provides for collections ordered by an attribute, but not uniquely identified by them. Depending on implementation, these would or would not support duplicate objects, but there seems little reason to allow duplicates if it is easy to prevent.
Core Concepts – Model Hierarchy
In constructing a model hierarchy for these collection classes there are a couple of issues. One is that we want to have an interface for Iterator, which is used in many places, and then an interface which defines the base for each of the two basic types of relationship collections – those with simple elements and those with key/value pairs. If we had inheritance of interfaces (rumored to be coming in OE11.0) we would have the base interface for the type inherit from Iterator and that base interface could be implemented by any class in the hierarchy.
But, in the absence of interface inheritance in the current language, we have a problem because we can’t use the base type interface as the type of a parameter in place of any of the concrete classes derived from it since it would then be missing the properties of Iterator. Therefore we have adopted the approach of creating an abstract class which implements the two interfaces, but with all abstract methods and then the concrete classes inherit from the abstract class, providing implementations for the methods.
Also, for each base type, there are multiple possible implementations (see Implementation Technologies) where each implementation would have the same overall signature, but might differ in performance, capacity, memory footprint, or whatever (see Performance Testing). Since it seems possible that one implementation will be preferable in some circumstances and another implementation preferable in others, we are electing to use a naming structure which will allow more than one concrete implementation for any abstract base type. E.g., there is an abstract base type called aIDSet, which is the collection class type for elements ordered by identity. If we created two concrete classes based on this abstract class, one using work-tables and one using temp-tables, we would call them WTIDSet and TTIDSet respectively. Both would have exactly the same signature and could be used interchangeably for the other by identifying the reference as aIDSet, but one or the other might be preferable in any given circumstance depending on requirements.
See the UML Diagrams for specifics of the structures of the two hierarchies.
Implementation Technologies
In the 2006 implementation, all collection classes were implemented using temp-tables based on the conclusion that temp-tables were a natural ABL language feature which provided a superset of capabilities needed for collection management. While this approach was effective and simple, since then concern has been raised about performance issues when the number of temp-tables in a session becomes large and about the excessive memory footprint and possibly instantiation penalty when a temp-table is used for a small and simple collection.
Unfortunately, ABL does not provide language constructs at a low enough level to make collections as simple as they are in 3GLs. That will require PSC implementing collections as a native language feature, which does not currently seem to be on the roadmap. Therefore, in this implementation we are exploring two other language constructs to provide support for collections – arrays and work-tables.
Arrays seem like a natural mechanism to support collections except that in ABL they cannot be dynamically resized once they are instantiated. While there special cases where one knows the upper bound maximum size of a collection in advance, the typical case is that one does not. Therefore, we are experimenting with an approach in which an initial array is sized to either a default size or a size specified by the programmer. If that array becomes full, then a second array is instantiated at a size which is the size of the original plus a default or programmer supplied growth factor. This will continue until a maximum of ten arrays is use. Logically they will be treated as one long array with the offset of any given index being computed as needed. While not completely open ended, like a temp-table, this approach can provide a relatively small initial array with a minimal memory footprint and yet can expand to handle an extremely large number of objects, probably more than can reasonably fit in memory.
Work-tables are a deprecated ABL language feature since, for most purposes their functionality is better covered by temp-tables. However, it seems likely that they have less memory overhead for small collections and for any collection which is just going to be accessed serially, their lack of an index is not a flaw. Currently, the documentation does not indicate that Progress..Lang.Object is a valid datatype for a work-table field. In practice, the compiler accepts such a definition, but a program will freeze if one tries to make an assignment to the field. Inquiries are in process about the possibility of getting full work-table support for Progress.Lang.Objects, but in the meantime a hybrid approach will be used, i.e., a work-table which provides the sort order for identity access with a pointer to an array which contains the actual object.
Performance testing will be used to determine if more than one implementation should be provided for each base type and which implementation will be preferred for the base type. Temp-tables are likely to continue to be used for key/value pair types, although this is only a small percentage of collection instances.
Performance Testing
Most relationship collections will contain only a handful of elements, but it is possible for a relationship to contain a large number of elements. Therefore, we are concerned with both the memory footprint of a class when it contains a small number of elements and with the performance of that class when it contains a large number of elements. In particular, the 2006 implementation used temp-tables throughout. This meant that they could be scaled to arbitrarily large numbers of elements and still perform adequately, but it also meant that a rather large amount of memory was consumed for a small collection.
Therefore, in developing these relationship collections classes we are looking at minimal memory footprint, scaling of memory footprint, and performance in a number of tasks. The tasks we have identified are:
- Add N objects to collection;
- Clear collection of N objects;
- Delete M random objects from a collection of N;
- Find M random objects from a collection of N by position (applicable only to List?*);
- Find M random objects from a collection of N by identity;
- Find M random objects from a collection of N by key;
- Iterate through M instances in a collection of N starting with first;
- Iterate through M instances in a collection of N starting with last;
- Delete M consecutive instances from a collection of N starting with I;
- Add M consecutive instances to a collection of N starting with I (only List?*)
Tests will be based on varying values of M, N, and I to identify any possible non-linearities. Testing will begin with smaller values and will be discontinued when results are judged unacceptable. Not all tests apply to all relationship base class types, i.e., one can only test access by keys in a base type which has keys.
It should be recognized that some of these tests will represent extreme stress tests compared to what one expects in practice in an application. For example, deleting 1000 random objects from a set of 10,000 would be quite extraordinary, both because few collections are likely to have even as many as 100 elements and because normal processing will be to fill a collection, process all elements one or more times, and then to clear and delete the collection as a whole. I.e., one typically will never delete even one element until such point as one is clearing the whole collection, which may be a far more efficient operation than deleting elements one by one. Nevertheless, relationship navigation is extremely common in OO programming, so identifying possible inefficiency is highly desirable.
* Note: List is a Java collection class type in which elements can be addressed by position, i.e., Nth. Currently, this does not seem to be a requirement for relationship collections and so is not included in the initial implementation, but it does seem like a useful class in other contexts and so is likely to appear in a later round of development.
Properties and Operators
Java collection classes have been provided with a fairly rich set of properties and operators, presumably based on the idea that these classes can then be used for a richer range of rôles, just as there are many classes in that same hierarchy which are clearly not intended for relationships at all. In the present implementation, the decision was made to focus on the essentials of object relationships with the idea of creating efficient, low impact infrastructure for OO programming and then to consider later whether there are other classes with other functions which could also be created. Therefore, this implementation uses minimal properties and operators.
Note that we are using a leading "a" to indicate an abstract class and a leading "i" to indicate an interface.
aSet
This is the abstract class for the most common collection type, that ordered only by the sequence in which elements are added to it. It has two read-only properties – Size (number of elements) and IsEmpty. It has and four operators:
- Add – adds the object in its parameter to the collection;
- Remove – removes the object in its parameter from the collection;
- Clear – removes all elements from the collection;
- Contains – returns a logical indicating whether the object parameter is in the collection; and
- Get Iterator - returns an Iterator object on the class.
Note that Contains will be inefficient on a large aSet and aIDSet is preferred if this is a regular need.
aIDSet
This is the abstract class for the simple collection type ordered by object identity. It has all of the same properties and operators as aSet plus one additional operator Get which has an integer argument and which returns the object with that identity.
aAttrKeySet
This is the abstract class which takes key/value pairs in which the key is considered an identifier for the object, i.e., keys must be unique. It has the same two properties as aSet. Its operators are:
- Add – parameters are a key/value pair which is added to the collection;
- GetValue – returns the object corresponding to the key in the parameter;
- RemoveKey – removes the key/value entry specified by the key in the parameter;
- RemoveValue – removes the key/value entry corresponding to the object in the parameter;
- Clear – removes all entries
- Contains – returns a logical indicating whether the object parameter is in the collection; and
- GetIterator – returns an Iterator on the keys.
aAttrSortSet
This is the abstract class which takes key/value pairs, but the key is considered only an attribute which defines sort order, not a unique key. It has the same properties and operators as aAttrKeySet except that GetValue is replaced by GetValues which return a collection of all objects in the collection with the key in the parameter.
iIterator
This is the interface which defines the signature for all collection iterators. It has two read-only properties – HasNext and HasPrev. Its operators are:
- First – positions at the first object in the collection and returns it;
- Next – advances to the next object in the collection and returns it;
- Last – positions at the last object in the collection and returns it;
- Prev – advances in reverse order to the previous object in the collection and returns it; and
- Remove – removes the object at the current position from the collection.
Note that we have considered whether the key/value collection classes should have both GetAttrIterator, i.e., on the keys, and GetIDIterator, i.e., on the ID of the objects, as this would be easy to do with a temp-table implementation. Currently, we are leaning toward just GetIterator on the keys as this seems in keeping with the needs of relationships.
UML Diagrams
Following are the UML class diagrams for the proposed implementation.
Note that RelationAttrSetOps will not be included in the initial implementation, but its definition is provided here to indicate where these operations will be implemented when and if they are needed.
iSet Family (click for larger version)

See below for higher resolution PDF.
iAttrSet Family (click for larger version)
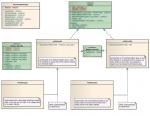
See below for higher resolution PDF.
Iterators
One of the factors which motivated this revision of Collection classes was a discussion on PEG which convinced me that I should allow for multiple iterators. In the Java Collection classes, Iterator is a separate interface and the GetIterator() method implements that interface to provide an Iterator for any given collection class. Since Iterator is separate and not limited to one instance, one has the structure to provide multiple simultaneous iterators for the same collection. In starting to work on this revision, we assumed that we would take this approach and you can see this reflected in the previously published material on this project.
However, in approaching actual coding of the project, we realized that there is an inherent problem because of the "intimacy" of iterators with respect to their collections. How can an iterator navigate the implementation structure of the collection without either having parts of that implementation be public, which would violate encapsulation, or having the collection have navigation methods, which would seem to violate normal form since both the collection and the iterator would be exposing very similar operations.
One solution proposed would be to have the navigation methods on the collection not be public to any except the iterator. That would still violate notions of OO purity, though less blatantly, but this is an academic question in the end since ABL has no level of protection which would provide this kind of limited access.
Another proposed solution was to have the navigation methods on the collection reference an "ID", the ID identifying the "current" record for a particular iterator. I.e., GetNext(ID) is GetNext relative to ID. If this ID was the actual object identifier, i.e., int(Obj), then the Iterator could determine the ID for the current element on its own. Otherwise, it would have to obtain this ID from the collection. Unfortunately, with the proposed array implementation for the most common type of collection, having the object ID would require an expensive search of the ID to identify the current record. Only an ID of the current element would be efficient there.
It was then observed that, while multiple iterators might sometimes be required of some types of collections, they seem highly unlikely in a relationship collection. They are unlikely because a relation is a connection between two object types in a parent child type of connection and the normal expectation is that if the parent does some operation on the children, it will do it to each of them, i.e., that one will navigate from the beginning to the end, an most often within the scope of a single method.
This raised the possibility that we would move the iterator back into the collection instead of making it something separate. Having thought of this, it was immediately appealing since it would guarantee that the navigation would be efficient relative to the specific implementation, but that all details of the implementation would be encapsulated within the class. This lead me to think that the Java structure is actually a less than ideal decomposition of the problem space since the need for navigation is inherent in the collection and separating them requires an overly intimate knowledge to be shared.
Having made this observation, I has now occurred to me that it would be possible to support multiple iterators within the collection itself by the use of named or numbered iterators. For example, GetIteratorID() could return a sequentially assigned integer which identifies a particular iterator. A small array in the collection, indexed by this integer, could then contain a value for the current record on that iterator. For an array implementation, it might be the current element number. For a work-table implementation it might be the Object ID to use in a find. For a temp-table implementation it might be the same object ID or a recid. Alternatively for a temp-table, one might have a separate query per iterator, but that seems like it would add weight. While the object ID and recid would require a FIND, this would be a C level operation and only one ABL instruction.
Revision of other parts of this specification is pending confirmation of our adoption of this approach.